Scala Module Configuration
This page goes into more detail about the various configuration options
for ScalaModule.
Many of the APIs covered here are listed in the Scaladoc:
Declarative Configuration
This example shows some of the common tasks you may want to override on a
ScalaModule: specifying the mainClass, adding additional
sources/resources, and setting compilation/run
options.
extends: [mill.scalalib.ScalaModule] # fully-qualified class name
scalaVersion: 3.7.4
mvnDeps:
- com.lihaoyi::scalatags:0.13.1
- com.lihaoyi::os-lib:0.11.4
# Add a custom maven repository URL
repositories: [https://oss.sonatype.org/content/repositories/releases]
# Set an explicit main class
mainClass: foo.Foo2
# Pin a specific JVM version, supports >=11
jvmVersion: 11
# Optionally specify the distribution: temurin, zulu, corretto, graalvm-community, etc.
# jvmVersion: temurin:11
# Add an additional source folder and resource folder, in addition to the default one
# Note the !append tag to append to the existing value rather than over-writing it
sources: !append [custom-src/]
resources: !append [custom-resources/]
# Configure compiler and runtime options and env vars
scalacOptions: [-deprecation, -Xfatal-warnings]
forkArgs: [-Dmy.custom.property=my-prop-value]
forkEnv: { MY_CUSTOM_ENV: my-env-value }> ./mill run
Foo2.value: <h1>hello2</h1>
Foo.value: <h1>hello</h1>
MyResource: My Resource Contents
MyOtherResource: My Other Resource Contents
my.custom.property: my-prop-value
MY_CUSTOM_ENV: my-env-value
> ./mill show assembly
".../out/assembly.dest/out.jar"
> ./out/assembly.dest/out.jar # mac/linux
Foo2.value: <h1>hello2</h1>
Foo.value: <h1>hello</h1>
MyResource: My Resource Contents
MyOtherResource: My Other Resource Contents
my.custom.property: my-prop-value> sed -i.bak 's/Foo2 {/Foo2 { println(Array("hello"): Seq[String])/g' custom-src/Foo2.scala
> ./mill compile # demonstrate -deprecation/-Xfatal-warnings flags
error: method copyArrayToImmutableIndexedSeq in class LowPriorityImplicits2 is deprecated since 2.13.0...This example demonstrates:
-
Adding third-party dependencies via
mvnDeps -
Setting an explicit
mainClass. Mill’sfoo.runby default will discover which main class to run from your compilation output, but if there is more than one or the main class comes from some library you can explicitly specify which one to use.mainClassalso adds the main class to yourfoo.jarandfoo.assemblyjars. -
Pass in JVM execution flags via
forkArgsor environment-variables viaforkEnv.
-
Pass compilation flags to the Scala compiler via
scalacOptions. -
Setting a
scalaVersion.
-
Adding custom
sourcesandresourcesfolders. -
Pinning a specific Java runtime/compile version via
jvmVersion
Paths such as custom-src/ or custom-resources/ are relative to the
moduleDir of the module being configured.
In the example above this is the root folder of your codebase, but in multi-module
projects this may be a subfolder containing the current package.mill.yaml file.
In the rare case where you need want to reference a path relative to the workspace root,
you can prefix it with // e.g. //src/
|
Most Tasks that you can define programmatically in a build.mill file can be specified
in a build.mill.yaml, as long as they involve simple configuration (strings, lists, maps, etc.)
and do not need Custom Build Logic.
For example, you can use the various configuration methods discussed in
Scala Library Dependencies: runMvnDeps, compileMvnDeps,
unmanagedClasspath, etc.
For more flexibility, e.g. if you need to generate sources or resource files at build time,
you can instead use Programmable Modules.
Scala Compiler Plugins
extends: ScalaModule
scalaVersion: 2.13.16
compileMvnDeps: [com.lihaoyi:::acyclic:0.3.18]
scalacOptions: [-P:acyclic:force]
scalacPluginMvnDeps: [com.lihaoyi:::acyclic:0.3.18]You can use Scala compiler plugins by setting scalacPluginMvnDeps. The above
example also adds the plugin to compileMvnDeps, since that plugin’s artifact
is needed on the compilation classpath (though not at runtime).
Remember that compiler plugins are published against the full Scala
version (eg. 2.13.16 instead of just 2.13), so when including them make sure to
use the ::: syntax shown above in the example.
|
> ./mill compile
...
error: Unwanted cyclic dependency
error: ...src/Foo.scala...
error: def y = Bar.z
error: ...src/Bar.scala...
error: def x = Foo.yScaladoc Config
To generate API documentation you can use the docJar task on the module you’d
like to create the docs for, configured via scaladocOptions:
extends: ScalaModule
scalaVersion: 3.3.6
# Configure ScalaDoc options
scalaDocOptions: [-siteroot, mydocs, -no-link-warnings]> ./mill show foo.docJar
"ref:...out/foo/docJar.dest/out.jar"
> unzip -p out/foo/docJar.dest/out.jar foo/Foo.html
...
...My Awesome Docs for class Foo...You can also browse the unpackaged directory directly under the scalaDocGenerated task.
> ./mill show foo.scalaDocGenerated
"ref:...out/foo/scalaDocGenerated.dest/javadoc"
> cat out/foo/scalaDocGenerated.dest/javadoc/foo/Foo.html
...
...My Awesome Docs for class Foo...When using Scala 3 you’re also able to use Scaladoc to generate a full static site next to your API documentation. This can include general documentation for your project and even a blog. While you can find the full documentation for this in the Scala 3 docs, below you’ll find some useful information to help you generate this with Mill.
By default, Mill will consider the site root as it’s called in
Scala 3
docs, to be the value of docResources(). It will look there for your
_docs/ and your _blog/ directory if any exist. Given a
project called bar:
Your project structure for this would look something like this:
. ├── build.mill ├── bar │ ├── docs │ │ ├── _blog │ │ │ ├── _posts │ │ │ │ └── 2022-08-14-hello-world.md │ │ │ └── index.md │ │ └── _docs │ │ ├── getting-started.md │ │ ├── index.html │ │ └── index.md │ └── src │ └── example │ └── Hello.scala
After generating your docs with mill example.docJar you’ll find by opening
your out/app/docJar.dest/javadoc/index.html locally in your browser you’ll
have a full static site including your API docs, your blog, and your
documentation.
> ./mill show bar.docJar
> unzip -p out/bar/docJar.dest/out.jar bar/Bar.html
...
...<p>My Awesome Docs for class Bar</p>...If you want to include source links, you can provide a path-to-URL mapping with the -source-links option.
def scalaDocOptions = Seq(
s"-source-links:${mill.api.BuildCtx.workspaceRoot}=github://owner/repo/main"
)Programmable Configuration
This example shows some of the common tasks you may want to override on a
ScalaModule, but using Mill’s programmable build.mill files rather
than the declarative build.mill.yaml files above. build.mill files
allow setting all the same keys as build.mill.yaml files, and additionally
can implement custom build logic such as def generatedSources below:
package build
import mill.*, scalalib.*
object `package` extends ScalaModule {
def scalaVersion = "3.8.2"
// You can have arbitrary numbers of third-party dependencies
def mvnDeps = Seq(
mvn"com.lihaoyi::scalatags:0.13.1",
mvn"com.lihaoyi::os-lib:0.11.4"
)
// Choose a main class to use for `.run` if there are multiple present
def mainClass: T[Option[String]] = Some("foo.Foo2")
// Add (or replace) source folders for the module to use
def customSources = Task.Sources("custom-src")
def sources = Task { super.sources() ++ customSources() }
// Add (or replace) resource folders for the module to use
def customResources = Task.Sources("custom-resources")
def resources = Task { super.resources() ++ customResources() }
// Generate sources at build time
def generatedSources: T[Seq[PathRef]] = Task {
for (name <- Seq("A", "B", "C")) os.write(
Task.dest / s"Foo$name.scala",
s"""
|package foo
|object Foo$name {
| val value = "hello $name"
|}
""".stripMargin
)
Seq(PathRef(Task.dest))
}
// Pass additional JVM flags when `.run` is called or in the executable
// generated by `.assembly`
def forkArgs: T[Seq[String]] = Seq("-Dmy.custom.property=my-prop-value")
// Pass additional environmental variables when `.run` is called. Note that
// this does not apply to running externally via `.assembly`
def forkEnv: T[Map[String, String]] = Map("MY_CUSTOM_ENV" -> "my-env-value")
// Additional Scala compiler options, e.g. to turn warnings into errors
def scalacOptions: T[Seq[String]] = Seq("-deprecation", "-Werror")
}If you want to better understand how the various upstream tasks feed into
a task of interest, such as run, you can visualize their relationships via
> ./mill visualizePlan run
(right-click open in new tab to see full sized)
You can also use your IDE’s autocompletion to explore what tasks are available to override and what each one does:
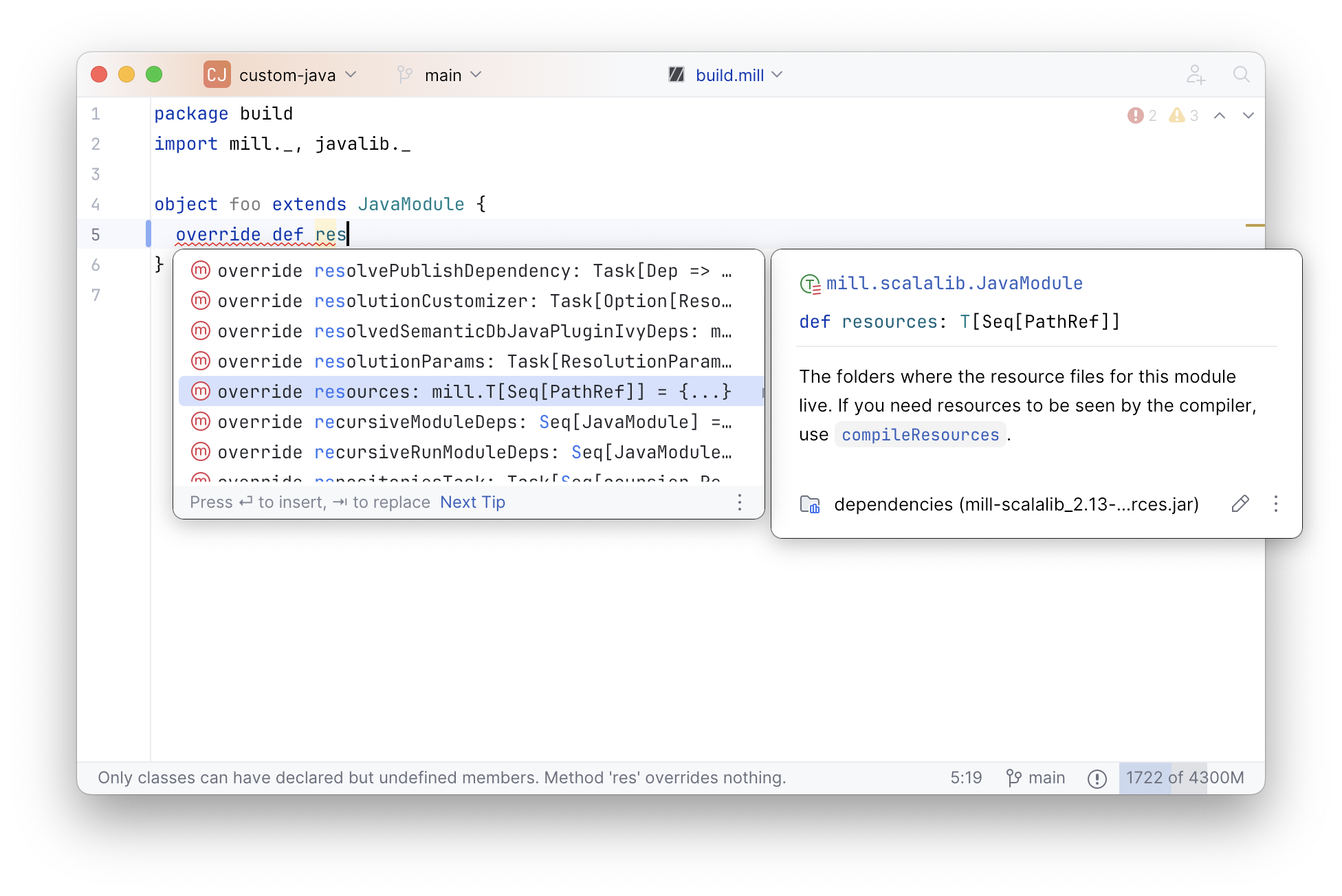
Note the use of moduleDir, Task.dest, and PathRef when performing
various filesystem operations:
-
moduleDirrefers to the base path of the module. For the root module, this is the root of the repo, and for inner modules it would be the module path e.g. for modulefoo.bar.quxthemoduleDirwould befoo/bar/qux. This can also be overridden if necessary -
Task.destrefers to the destination folder for a task in theout/folder. This is unique to each task, and can act as both a scratch space for temporary computations as well as a place to put "output" files, without worrying about filesystem conflicts with other tasks -
PathRefis a way to return the contents of a file or folder, rather than just its path as a string. This ensures that downstream tasks properly invalidate when the contents changes even when the path stays the same
> ./mill run
Foo2.value: <h1>hello2</h1>
Foo.value: <h1>hello</h1>
FooA.value: hello A
FooB.value: hello B
FooC.value: hello C
MyResource: My Resource Contents
MyOtherResource: My Other Resource Contents
my.custom.property: my-prop-value
MY_CUSTOM_ENV: my-env-value
> ./mill show assembly
".../out/assembly.dest/out.jar"
> ./out/assembly.dest/out.jar # mac/linux
Foo2.value: <h1>hello2</h1>
Foo.value: <h1>hello</h1>
FooA.value: hello A
FooB.value: hello B
FooC.value: hello C
MyResource: My Resource Contents
MyOtherResource: My Other Resource Contents
my.custom.property: my-prop-value> sed -i.bak 's/Foo2 {/Foo2 { println(Array("hello"): Seq[String])/g' custom-src/Foo2.scala
> ./mill compile # demonstrate -deprecation/-Xfatal-warnings flags
error: method copyArrayToImmutableIndexedSeq in class LowPriorityImplicits2 is deprecated since 2.13.0...Custom Tasks
This example shows how to define task that depend on other tasks:
-
For
generatedSources, we override the task and make it depend directly onmvnDepsto generate its source files. In this example, to include the list of dependencies as tuples within a staticobject -
For
lineCount, we define a brand new task that depends onsources, and then overrideforkArgsto use it. That lets us access the line count at runtime usingsys.propsand print it when the program runs
package build
import mill.*, scalalib.*
object `package` extends ScalaModule {
def scalaVersion = "3.8.2"
def mvnDeps = Seq(mvn"com.lihaoyi::mainargs:0.7.8")
def generatedSources: T[Seq[PathRef]] = Task {
val prettyMvnDeps = for (ivyDep <- mvnDeps()) yield {
val org = ivyDep.organization
val name = ivyDep.name
val version = ivyDep.version
s"""("$org", "$name", "$version")"""
}
os.write(
Task.dest / s"MyDeps.scala",
s"""
|package foo
|object MyDeps {
| val value = List(
| ${prettyMvnDeps.mkString(",\n")}
| )
|}
""".stripMargin
)
Seq(PathRef(Task.dest))
}
def lineCount: T[Int] = Task {
sources()
.flatMap(pathRef => os.walk(pathRef.path))
.filter(_.ext == "scala")
.map(os.read.lines(_).size)
.sum
}
def forkArgs: T[Seq[String]] = Seq(s"-Dmy.line.count=${lineCount()}")
def printLineCount() = Task.Command { println(lineCount()) }
}The above build defines the customizations to the Mill task graph shown below, with the boxes representing tasks defined or overridden above and the un-boxed labels representing existing Mill tasks:
Mill lets you define new cached Tasks using the Task {…} syntax,
depending on existing Tasks e.g. foo.sources via the foo.sources()
syntax to extract their current value, as shown in lineCount above. The
return-type of a Task has to be JSON-serializable (using
uPickle, one of Mill’s Bundled Libraries)
and the Task is cached when first run until its inputs change (in this case, if
someone edits the foo.sources files which live in foo/src). Cached Tasks
cannot take parameters.
Note that depending on a task requires use of parentheses after the task
name, e.g. mvnDeps(), sources() and lineCount(). This converts the
task of type T[V] into a value of type V you can make use in your task
implementation.
This example can be run as follows:
> ./mill run --text hello
text: hello
MyDeps.value: List((com.lihaoyi,mainargs,0.7.8))
my.line.count: 14
> ./mill show lineCount
14
> ./mill printLineCount
14Custom tasks can contain arbitrary code. Whether you want to
download files using requests.get, shell-out to Webpack
to compile some Javascript, generate sources to feed into a compiler, or
create some custom jar/zip assembly with the files you want , all of these
can simply be custom tasks with your code running in the Task {…} block.
You can also import arbitrary Java or Scala libraries from Maven Central via
//| mvnDeps to use in your build.
You can create arbitrarily long chains of dependent tasks, and Mill will
handle the re-evaluation and caching of the tasks' output for you.
Mill also provides you a Task.dest folder for you to use as scratch space or
to store files you want to return:
-
Any files a task creates should live within
Task.dest -
Any files a task modifies should be copied into
Task.destbefore being modified. -
Any files that a task returns should be returned as a
PathRefto a path withinTask.dest
That ensures that the files belonging to a particular task all live in one place, avoiding file-name conflicts, preventing race conditions when tasks evaluate in parallel, and letting Mill automatically invalidate the files when the task’s inputs change.
Generated Sources
package build
import mill.*, scalalib.*
object foo extends ScalaModule {
def scalaVersion = "3.8.2"
def generatedSources = Task {
os.write(
Task.dest / "Foo.scala",
"""package foo
|object Foo {
| def main(args: Array[String]): Unit = {
| println("Hello World")
| }
|}
""".stripMargin
)
Seq(PathRef(Task.dest))
}
}In Mill, you can override the def generatedSources task to write files to disk that
will be added to the module’s source folders during compilation. The example above
generates a simple main method during build time that can be compiled and then
used at runtime, but you can write arbitrarily code inside generatedSources to
generated the sources you need.
> ./mill foo.run
Hello WorldClasspath and Filesystem Resources
package build
import mill.*, scalalib.*
object foo extends ScalaModule {
def scalaVersion = "3.8.2"
def mvnDeps = Seq(
mvn"com.lihaoyi::os-lib:0.11.4"
)
object test extends ScalaTests {
def mvnDeps = Seq(mvn"com.lihaoyi::utest:0.9.1")
def testFramework = "utest.runner.Framework"
def otherFiles = Task.Source("other-files")
def forkEnv = super.forkEnv() ++ Map(
"OTHER_FILES_DIR" -> otherFiles().path.toString
)
}
}> ./mill foo.test
... foo.FooTests...simple ...
...This section discusses how tests can depend on resources locally on disk.
Mill provides two ways to do this: via the JVM classpath resources, and via
the resource folder which is made available as the environment variable
MILL_TEST_RESOURCE_DIR available in test suites:
-
The classpath resources are useful when you want to fetch individual files, and are bundled with the application by the
.assemblystep when constructing an assembly jar for deployment. But they do not allow you to list folders or perform other filesystem operations. -
The resource folder, available via
MILL_TEST_RESOURCE_DIR, gives you access to the folder path of the resources on disk. This is useful in allowing you to list and otherwise manipulate the filesystem, which you cannot do with classpath resources. However, theMILL_TEST_RESOURCE_DIRonly exists when running tests using Mill, and is not available when executing applications packaged for deployment via.assembly -
Apart from
resources/, you can provide additional folders to your test suite by defining aTask.Source(otherFilesabove) and passing it toforkEnv. This provide the folder path as an environment variable that the test can make use of
Example application code demonstrating the techniques above can be seen below:
package foo
object Foo {
def classpathResourceText = os.read(os.resource / "file.txt")
}package foo
import utest.*
object FooTests extends TestSuite {
def tests = Tests {
test("simple") {
// Reference app module's `Foo` class which reads `file.txt` from classpath
val appClasspathResourceText = Foo.classpathResourceText
assert(appClasspathResourceText == "Hello World Resource File")
// Read `test-file-a.txt` from classpath
val testClasspathResourceText = os.read(os.resource / "test-file-a.txt")
assert(testClasspathResourceText == "Test Hello World Resource File A")
// Use `MILL_TEST_RESOURCE_DIR` to read `test-file-b.txt` from filesystem
val testFileResourceDir = os.Path(sys.env("MILL_TEST_RESOURCE_DIR"))
val testFileResourceText = os.read(testFileResourceDir / "test-file-b.txt")
assert(testFileResourceText == "Test Hello World Resource File B")
// Use `MILL_TEST_RESOURCE_DIR` to list files available in resource folder
assert(
os.list(testFileResourceDir).sorted ==
Seq(testFileResourceDir / "test-file-a.txt", testFileResourceDir / "test-file-b.txt")
)
// Use the `OTHER_FILES_DIR` configured in your build to access the
// files in `foo/test/other-files/`.
val otherFileText = os.read(os.Path(sys.env("OTHER_FILES_DIR")) / "other-file.txt")
assert(otherFileText == "Other Hello World File")
}
}
}Tests by default only have access to their classpath resources and
resource folder as mentioned above. They cannot read random project files on disk,
and require that you pass in any other
files or folders that they require explicitly (e.g. def otherFiles above).
This is necessary so that Mill can ensure the necessary files are in place
before the test begins running, and so -w/--watch knows it needs to re-run
the tests if those files changed. Thus your tests cannot just read project files
direct off disk via new FileInputStream("foo/resources/test-file-a.txt").
Mill runs test processes in a sandbox/ folder, rather
than in your project root folder, to enforce this.
If you have legacy tests that need to run in the project root folder to work, you
can configure your test suite with def testSandboxWorkingDir = false to disable
the sandbox and make the tests run in the project root.
Cross-Scala-Version Modules
package build
import mill.*, scalalib.*
val scalaVersions = Seq("2.12.20", "2.13.16")
object foo extends Cross[FooModule](scalaVersions)
trait FooModule extends CrossScalaModule {
def moduleDeps = Seq(bar())
}
object bar extends Cross[BarModule](scalaVersions)
trait BarModule extends CrossScalaModuleThis is an example of cross-building a module across multiple Scala
versions. Each module is replaced by a Cross module, which is given a list
of strings you want the cross-module to be replicated for. You can then
specify the cross-modules with square brackets when you want to run tasks on
them.
CrossScalaModule supports both shared sources within src/ as well as
version specific sources in src-x/, src-x.y/, or src-x.y.z/ that
apply to the cross-module with that version prefix.
> ./mill resolve __.run
foo.2_12_20.run
foo.2_13_16.run
bar.2_12_20.run
bar.2_13_16.run
> ./mill foo.2_12_20.run
Foo.value: Hello World Scala library version 2.12.20...
Bar.value: bar-value
Specific code for Scala 2.x
Specific code for Scala 2.12.x
> ./mill foo.2_13_16.run
Foo.value: Hello World Scala library version 2.13.16...
Bar.value: bar-value
Specific code for Scala 2.x
Specific code for Scala 2.13.x
> ./mill bar.2_13_16.run
Bar.value: bar-valueCrossScalaModules can depend on each other using moduleDeps, but require
the () suffix in moduleDeps to select the appropriate instance of the
cross-module to depend on. You can also pass the crossScalaVersion
explicitly to select the right version of the cross-module:
object foo2 extends Cross[Foo2Module](scalaVersions)
trait Foo2Module extends CrossScalaModule {
def moduleDeps = Seq(bar(crossScalaVersion))
}
object bar2 extends Cross[Bar2Module](scalaVersions)
trait Bar2Module extends CrossScalaModuleUnidoc
package build
import mill.*, scalalib.*
object foo extends ScalaModule, UnidocModule {
def scalaVersion = "3.8.2"
def moduleDeps = Seq(bar, qux)
object bar extends ScalaModule {
def scalaVersion = "3.8.2"
}
object qux extends ScalaModule {
def scalaVersion = "3.8.2"
def moduleDeps = Seq(bar)
}
def unidocDocumentTitle = Task { "foo docs" }
def unidocVersion = Some("0.1.0")
def unidocSourceUrl = Some("https://github.com/lihaoyi/test/blob/master")
}This example demonstrates use of mill.scalalib.UnidocModule. This can be
mixed in to any ScalaModule, and generates a combined Scaladoc for the
module and all its transitive dependencies. Two tasks are provided:
-
.unidocLocal: this generates a site suitable for local browsing. If unidocSourceUrl is provided, the scaladoc provides links back to the local sources -
.unidocSite: this generates a site suitable for local browsing. If unidocSourceUrl is provided, the scaladoc provides links back to the sources as browsable from theunidocSourceUrlbase (e.g. on Github)
> ./mill show foo.unidocLocal
".../out/foo/unidocLocal.dest"
> cat out/foo/unidocLocal.dest/foo/Foo.html
...
...My Eloquent Scaladoc for Foo...
> cat out/foo/unidocLocal.dest/foo/qux/Qux.html
...
...My Excellent Scaladoc for Qux...
> cat out/foo/unidocLocal.dest/foo/bar/Bar.html
...
...My Lucid Scaladoc for Bar...
> ./mill show foo.unidocSiteUsing the Ammonite Repl / Scala console
All ScalaModules have a console and a repl task, to start a Scala console or an Ammonite Repl.
When using the console, you can configure its scalac options using the consoleScalacOptions task.
For example, you may want to inherit all of your regular scalacOptions but disable -Xfatal-warnings:
consoleScalacOptions to disable fatal warningsimport mill.*, scalalib.*
object foo extends ScalaModule {
def consoleScalacOptions = scalacOptions().filterNot(o => o == "-Xfatal-warnings")
}To use the repl, you can (and sometimes need to) customize the Ammonite version to work with your selected Scala version.
Mill provides a default Ammonite version,
but depending on the Scala version you are using, there may be no matching Ammonite release available.
In order to start the repl, you may have to specify a different available Ammonite version.
ammoniteVersion to select a release compatible to the scalaVersionimport mill.*, scalalib.*
object foo extends ScalaModule {
def scalaVersion = "2.12.6"
def ammoniteVersion = "2.4.0"
}|
Why is Ammonite tied to the exact Scala version? This is because Ammonite depends on the Scala compiler. In contrast to the Scala library, compiler releases do not guarantee any binary compatibility between releases. As a consequence, Ammonite needs full Scala version specific releases. The older your used Mill version or the newer the Scala version you want to use, the higher is the risk that the default Ammonite version will not match. |
Disabling incremental compilation with Zinc
By default all ScalaModules use incremental compilation via Zinc to
only recompile sources that have changed since the last compile, or ones that have been invalidated
by changes to upstream sources.
If for any reason you want to disable incremental compilation for a module, you can override and set
zincIncrementalCompilation to false
build.millimport mill.*, scalalib.*
object foo extends ScalaModule {
def zincIncrementalCompilation = false
}Using a Scala nightly version
Scala nightly versions are published to https://repo.scala-lang.org/artifactory/maven-nightlies.
If you want to build against a Scala nightly version, you need to add the
Maven repository to your configuration.
For convenience, we have a constant defined under
CoursierModule.KnownRepositories.ScalaLangNightlies.
Since you want to change the Scala tool chain, which is provided by the JvmWorkerModule,
you also need to configure the repository in a dedicated JvmWorker instannce.
package build
import mill.*
import mill.api.*
import mill.scalalib.*
object JvmWorker extends JvmWorkerModule {
override def repositories =
super.repositories() ++ Seq(CoursierModule.KnownRepositories.ScalaLangNightlies)
}
object foo extends ScalaModule {
override def jvmWorker: ModuleRef[JvmWorkerModule] = ModuleRef(JvmWorker)
override def repositories =
super.repositories() ++ Seq(CoursierModule.KnownRepositories.ScalaLangNightlies)
override def scalaVersion = "3.8.0-RC1-bin-20250825-ee2f641-NIGHTLY"
override def mvnDeps = Seq(
mvn"org.scala-lang.modules::scala-xml:2.4.0"
)
}> mill foo.run You
Hello You!Integrating Declarative and Programmatic Config
Custom Module Traits
Declarative Scala modules can inherit from user-defined traits via extends,
and are not limited to the builtin traits provided by Mill:
package millbuild
import mill.*, scalalib.*
trait LineCountScalaModule extends mill.scalalib.ScalaModule {
/** Total number of lines in module source files */
def lineCount = Task {
allSourceFiles().map(f => os.read.lines(f.path).size).sum
}
/** Generate resources using lineCount of sources */
override def resources = Task {
os.write(Task.dest / "line-count.txt", "" + lineCount())
super.resources() ++ Seq(PathRef(Task.dest))
}
}> ./mill run
...
Line Count: 17
> ./mill show lineCount
17Programmable moduleDeps
Declarative modules can depend on programmable modules, and vice versa. This
allows you to use simple declarative build.mill.yaml files for modules without any special
requirements, use programmable build.mill files for modules with custom tasks or other
more advanced customizations, and have them inter-operate with each other seamlessly.
The example below shows a declarative module in foo/package.mill.yaml depending upon
a programmable module bar and a programmable cross-module qux[1].
package build
import mill.*, scalalib.*
object bar extends ScalaModule {
def scalaVersion = "3.8.2"
def mvnDeps = Seq(mvn"com.lihaoyi::scalatags:0.13.1")
}
object qux extends Cross[QuxModule](1, 2, 3)
trait QuxModule extends ScalaModule, Cross.Module[Int] {
def scalaVersion = "3.8.2"
}extends: ScalaModule
moduleDeps: [bar, "qux[1]"]
scalaVersion: 3.8.2
mvnDeps: [com.lihaoyi::mainargs:0.7.8]> ./mill foo.run --text hello
<h1>hello</h1>The dependenies on programmable modules like bar and cross-modules like qux[1] use
Mill’s Task Query Syntax. Note that "qux[1]" needs to be
quoted to avoid being mistaken for the YAML [] array syntax.