The Mill Build Engineering Blog
Welcome to the Mill build engineering blog! This is the home for articles on technical topics related to JVM platform tooling and language-agnostic build tooling, some specific to the Mill build tool but mostly applicable to anyone working on build tooling for large codebases in JVM and non-JVM languages.
Spring Boot, Micronaut and Quarkus with Mill
Vasilis Nicolaou, May 2026
In this post, we explore how the Mill build tool supports these frameworks, providing a faster and smoother developer experience than traditional build tools like Maven and Gradle.
Spring Boot, Micronaut and Quarkus each expect different things from a build tool. Spring Boot layers AOT and native support on top of a conventional JVM build, Micronaut adds an explicit AOT pipeline and Quarkus takes over much more of packaging and dependency modelling.
Making Scala Scripting Actually Good with Mill
Li Haoyi, 28 March 2026
Writing scripts in the Scala language has been possible for decades, but it has never been polished enough to actually use in practice: poor library support, IDE support, integration with larger projects, etc.. In this article we will walk through the 20-year history of Scala scripting, see how each attempt has improved various parts of the scripting experience, and shows how the Mill build tool’s new script support finally resolves all the long-standing issues, making Scala scripts a viable way to write code as part of your larger codebase or monorepo.
Scripting on the JVM with Java, Scala, and Kotlin
Li Haoyi, 12 February 2026
Lots of people write code in Java, Scala, or Kotlin, but that code is normally relegated to large enterprise codebases. This article will explore the pros and cons of using JVM languages for small-scale scripting instead, as an alternative to Python, Javascript, or Bash:
-
How the performance and compile-time safety of the JVM are advantages over scripting languages
-
How verbosity, build tool overhead, and lack of script-focused libraries cause issues
-
How lightweight languages, tooling, and libraries are able to smooth over some of those issues
By the end of this article, you will see how the JVM can be truly a world-class scripting environment as robust and convenient as any scripting language out there.
How To Publish to Maven Central Easily with Mill
Li Haoyi, 4 Feb 2026
Traditionally setting up a Java, Scala, or Kotlin project to be published to Maven Central - the de-facto standard JVM package repository - has always been a bit involved. You need to install GPG (or PGP???), create your keys (don’t forget to upload them via send-key!), set up multiple build tool plugins, figure out how to set up secrets to publish from your CI pipeline, and so on. This article explores how the Mill build tool makes it easy to publish to Maven Central, so that anyone can easily package and upload their code to share it with the rest of the JVM community.
Simpler JVM Project Setup with Mill 1.1.0
Li Haoyi, 27 Jan 2026
Java and other JVM languages like Scala or Kotlin are often used for large enterprise codebases,
but the friction of configuring their tooling means they are less often used for small
programs or scripts. The new release of the Mill build tool v1.1.0
(changelog)
contains two features that try to improve upon this pain point, allowing your projects
to be configured via a compact build.mill.yaml file, rather than a verbose pom.xml:
build.mill.yamlextends: JavaModule
mvnDeps:
- org.jsoup:jsoup:1.7.2
- org.slf4j:slf4j-nop:2.0.7And letting single-file programs be configured by a //| build header comment
at the top of the file:
HtmlScraper.java//| mvnDeps:
//| - org.jsoup:jsoup:1.7.2
import org.jsoup.Jsoup;
public class HtmlScraper {
...
}> ./mill HtmlScraper.java Singapore 1
Hokkien
Conscription_in_Singapore
Malaysia_Agreement
Government_of_Singapore
...This blog post will dive into these two new features: how they work, why they are interesting, and where they learn from or improve upon existing tools in the JVM ecosystem. We hope these features will streamline the process of setting up a project in Java, Scala, and Kotlin, making the JVM languages an attractive and easy way to write small-scale programs and scripts.
Zero-Setup Java Build Tooling via Mill Bootstrap Scripts
Li Haoyi, 24 September 2025
Getting the software you need installed onto your machine is a common point of
friction, whether you’re on OS-X finding
Homebrew being terribly slow or on Ubuntu finding
the versions available are all outdated.
Setting up Java projects in particular often involves a multi-step process to install mvn,
sdkman, jenv, and the java version you need.
The Mill build tool does something interesting here: it requires no system-wide installation
at all to build your Java projects! You can checkout any codebase built with Mill on a bare
Linux/Mac/Windows machine, build it without any prior setup using it’s ./mill bootstrap
script, and Mill will automatically download and cache itself, any JVMs, and any third-party
libraries and tools necessary. For example, the ./mill __.compile below is all that is needed
to compile all modules in a newly-checked-out Mill project on a clean machine, greatly
simplifying building your project on diverse dev and CI environments:
> curl -L https://github.com/com-lihaoyi/cask/archive/refs/heads/master.zip -o cask.zip
> unzip cask.zip && cd cask-master
> ./mill __.compileThis blog post explores how Mill’s zero-install workflow works: the status quo, the interesting innovations that Mill builds upon, and Mill’s unique ideas that let it achieve this zero-setup usage to greatly simplify getting started working with Java, Scala, or Kotlin projects.
Mill as an Alternative Android Build Tool
Vasilis Nicolaou, 17 September 2025
Until recently, Gradle was the only realistic option for Android builds. Today, Mill provides an alternative to Gradle that is easier to use and learn.
In less than a year, Mill went from minimal Android support to producing installable APKs for projects as complex as:
Writing Your Own Simple Tab-Completions for Bash and Zsh
Li Haoyi, 7 August 2025
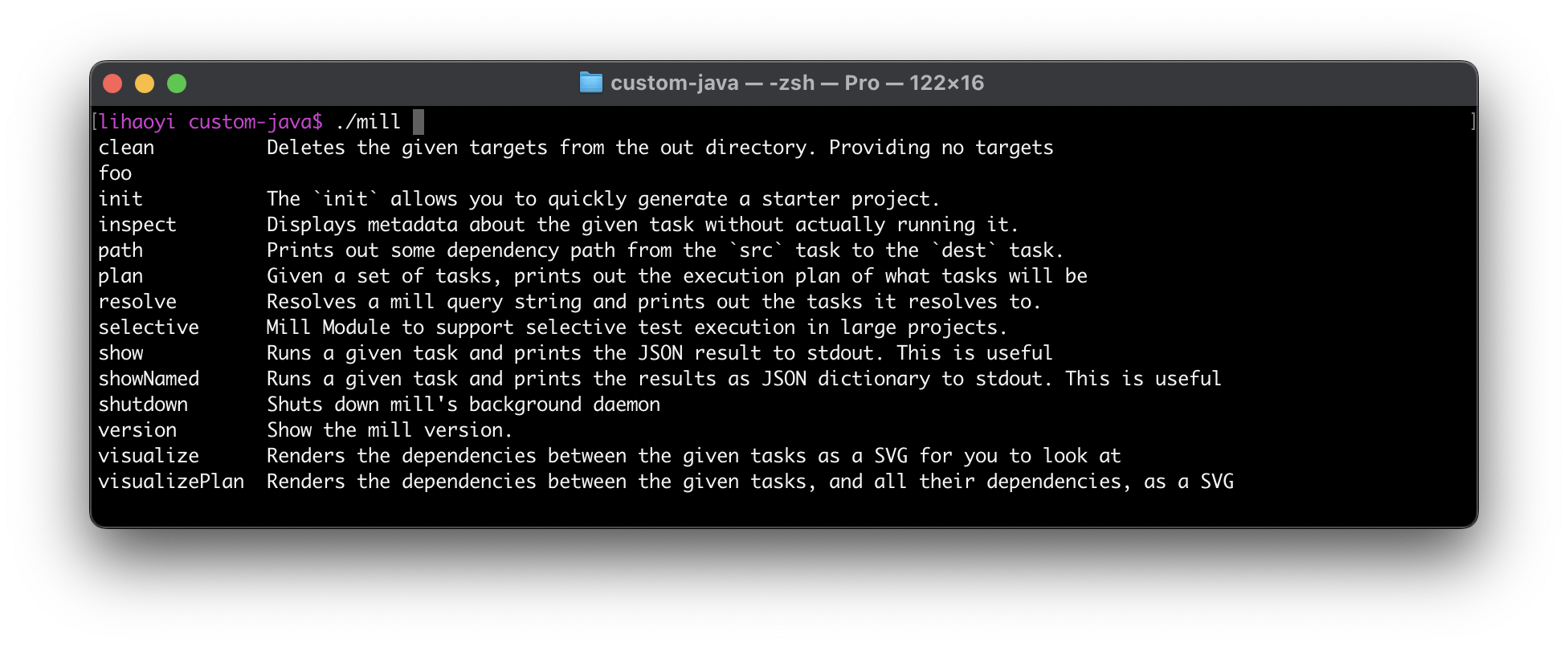
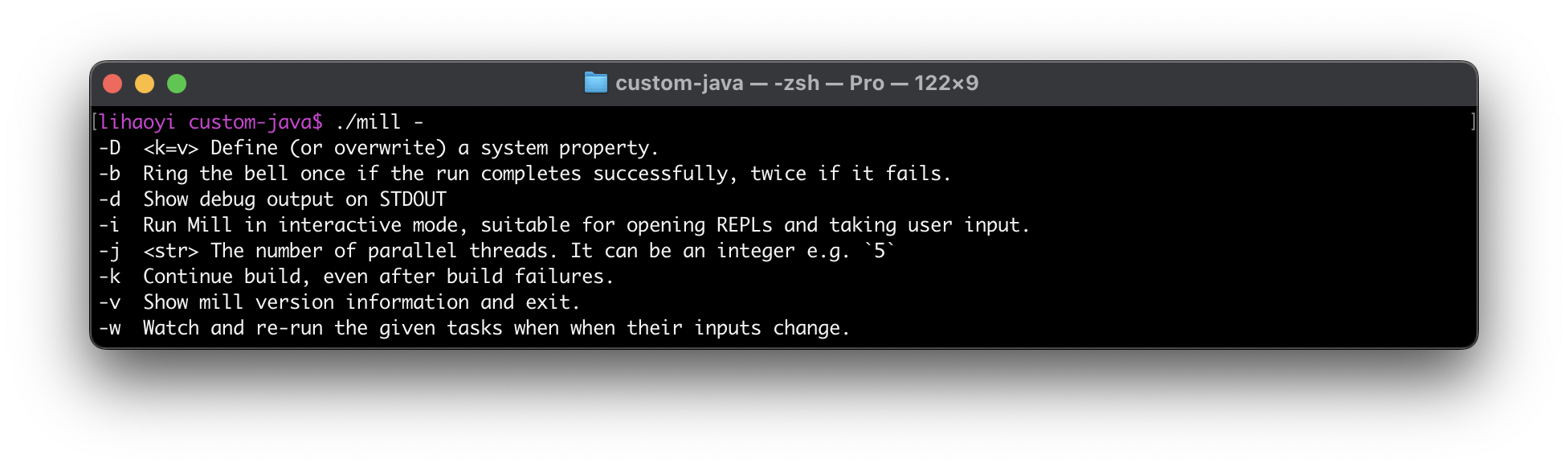
Shell tab-completions can be very handy, but setting them up is complicated by the fact that half your users would be using Bash-on-Linux, while the other half will be using Zsh-on-OSX, each of which has different tab-completion APIs. Furthermore, most users exploring an unfamiliar CLI tool using tab completion appreciate showing a description along with each completion so they can read what it is, but that’s normally only available on Zsh and not on Bash.
But with some work, you can make your tab-completions work on both shells, including nice quality-of-life features like completion descriptions. This blog post will explore how it can be done, based on our recent experience implementing this in the Mill build tool version 1.0.3, providing the great tab-completion experience you see below in a way that works across both common shells. Hopefully based on this, you will know enough and have enough reference examples to set up Bash and Zsh completions for your own command-line tooling.
Mill Build Tool v1.0.0 Release Highlights
Li Haoyi, 10 July 2025
Mill is a build tool for Java, Scala, and Kotlin that aims to improve upon existing build tools in areas like Mill Build Performance, extensibility, and IDE support. The new release of Mill 1.0.0 is a major breaking version of the Mill project focused on setting a solid technical foundation that can provide stability for the coming years of development. While the Changelog contains a thorough listing of the various changes, as well as detailed migration instructions, this article instead spends more time discussing some of the highlights of the Mill 1.0.0 release.
Mill as a Direct Style Build Tool
Li Haoyi, 10 May 2025
Mill is a JVM build tool that targets Java/Scala/Kotlin and has potential to serve the large-monorepo codebases that Bazel currently serves. Mill has good traction among its users, benchmarks that demonstrate 3-6x faster builds than its competitors, and a unique "direct-style" design that make it easy to use and extend. This page discusses one of the most interesting design decisions in Mill, and how it sets Mill apart from other build tools on the market.
Strategies for Efficiently Parallelizing JVM Test Suites
Li Haoyi, 17 March 2025
Test suites are in theory the ideal workload to parallelize, as they usually contain a large number of independent tests that can each be run in parallel. But implementing parallelism in practice can be challenging: a naive implementation can easily result in increased resource usage without any speedup, or even slow things down compared to running things on a single thread.
This blog post will explore the design and evolution of the Mill JVM build tool’s test parallelism strategy, from its start as a simple serial test runner, to naive module-based and class-based sharding, to the dynamic sharding strategy implemented in the latest version of Mill 0.12.9. We will discuss the pros and cons of the different approaches to test parallelization, analyze how they perform both theoretically and with benchmarks, and compare them to the runtime characteristics of other build tool test runners.
Invalidating build caches using JVM bytecode callgraph analysis
Li Haoyi, 10 March 2025
Build tools often cache your task outputs and invalidate them when the input files change, and build tools often let you implement tasks using blocks of arbitrary code in some general-purpose language. But the combination of these raises a question: if your tasks can contain arbitrary code, how can you detect when that code has changed, and appropriately invalidate the task’s caches? In most programming languages, "blocks of arbitrary code" are opaque - and the only thing you can do is run them - so this problem is unsolvable.
This blog post explores how Mill extends its JVM runtime by analyzing the callgraph of your build logic at a bytecode level. This lets Mill analyze a task’s code-block to detect changes in its implementation or that of transitively-called methods, letting us automatically invalidate task caches when the code is modified. We’ll discuss the implementation and limitations of this bytecode analysis, and show empirically how this is able to provide a significant improvement over more naive approaches to the problem.
Fast Incremental JVM Assembly Jar Creation with Mill
Li Haoyi, 16 February 2025
Assembly jars are a convenient deployment format for JVM applications, bundling your application code and resources into a single file that can run anywhere a JVM is installed. But assembly jars can be slow to create, which can slow down iterative development workflows that depend on them. The Mill JVM build tool uses some special tricks to let you iterate on your assembly jars much faster than traditional build tools like Maven or Gradle, cutting down their incremental creation time from 10s of seconds to less than a second. This can substantially increase your developer productivity by saving time you would otherwise spend waiting for your assembly to be created.
What does a Build Tool do?
Li Haoyi, 13 February 2025
The most common question I get asked about the Mill build tool is: what does a build
tool even do? Even software developers may not be familiar with the idea: they may run
pip install and python foo.py, javac Foo.java, or go build or some other
language-specific CLI directly. They may have a folder full of custom Bash scripts
they use during development. Or they may develop software on a team where someone
else has set up the tooling that they use. This blog post explores what build tools
are all about, why they are important to most software projects as they scale, and
how they work under the hood.
How to Compile Java into Native Binaries with Mill and Graal
Li Haoyi, 1 February 2025
One recent development is the ability to compile Java programs into self-contained native binaries. This provides more convenient single-file distributions, faster startup time, and lower memory footprint, at a cost of slower creation time and limitations around reflection and dynamic classloading. This article explores how you can get started building your Java program into a native binary, using the Mill build tool and the Graal native-image compiler, and how to think about the benefits and challenges of doing so.
Understanding JVM Garbage Collector Performance
Li Haoyi, 10 January 2025
Garbage collectors are a core part of many programming languages. While they generally work well, on occasion when they go wrong they can fail in very unintuitive ways. This article will discuss the fundamental design of how garbage collectors work, and tie it to real benchmarks of how GCs perform on the Java Virtual Machine. You should come away with a deeper understanding of how the JVM garbage collector works and concrete ways you can work to improve its performance in your own real-world projects.
How JVM Executable Assembly Jars Work
Li Haoyi, 2 January 2025
One feature of the Mill JVM build tool is that the assembly jars it creates are directly executable:
> ./mill show foo.assembly # generate the assembly jar
"ref:v0:bd2c6c70:/Users/lihaoyi/test/out/foo/assembly.dest/out.jar"
> out/foo/assembly.dest/out.jar # run the assembly jar directly
Hello WorldOther JVM build tools also can generate assemblies, but most need you to run them
via java -jar or java -cp,
or require you to use jlink or
jpackage
which are much more heavyweight and troublesome to set up. Mill automates that, and while not
groundbreaking, it is a nice convenience that makes your JVM
code built with Mill fit more nicely into command-line centric workflows common in modern
software systems.
This article will discuss how Mill’s executable assemblies are implemented, so perhaps other build tools and toolchains will be able to provide the same convenience
How To Manage Flaky Tests in your CI Workflows
Li Haoyi, 1 January 2025
Many projects suffer from the problem of flaky tests: tests that pass or fail non-deterministically. These cause confusion, slow development cycles, and endless arguments between individuals and teams in an organization.
This article dives deep into working with flaky tests, from the perspective of someone who built the first flaky test management systems at Dropbox and Databricks and maintained the related build and CI workflows over the past decade. The issue of flaky tests can be surprisingly unintuitive, with many "obvious" approaches being ineffective or counterproductive. But it turns out there are right and wrong answers to many of these issues, and we will discuss both so you can better understand what managing flaky tests is all about.
Faster CI with Selective Testing
Li Haoyi, 24 December 2024
Selective testing is a key technique necessary for working with any large codebase or monorepo: picking which tests to run to validate a change or pull-request, because running every test every time is costly and slow. This blog post will explore what selective testing is all about, the different approaches you can take with selective testing, based on my experience working on developer tooling and CI for the last decade at Dropbox and Databricks. Lastly, we will discuss how the Mill build tool supports selective testing.
Why Use a Monorepo Build Tool?
Li Haoyi, 17 December 2024
Software build tools mostly fall into two categories:
One question that comes up constantly is why do people use Monorepo build tools? Tools like Bazel are orders of magnitude more complicated and hard to use than tools like Poetry or Cargo, so why do people use them at all?
How Fast Does Java Compile?
Li Haoyi, 29 November 2024
Java compiles have the reputation for being slow, but that reputation does not match today’s reality. Nowadays the Java compiler can compile "typical" Java code at over 100,000 lines a second on a single core. That means that even a million line project should take more than 10s to compile in a single-threaded fashion, and should be even faster in the presence of parallelism