The Output Directory
Mill puts all its output in the top-level out/ folder.
The out/ folder contains all the generated files & metadata for your build.
It holds some files needed to manage Mill’s longer running server instances
(out/mill-daemon/*) as well as a directory and file structure resembling the
project’s module structure.
For the purposes of this page, we will be using the following minimal Mill build
package build
import mill.*, javalib.*
object foo extends JavaModule {}> ./mill foo.compile # compile once
> echo "" >> foo/src/foo/Foo.java
> ./mill foo.compile # compile again after editing a file
> find out
out/foo/compile.dest/...
out/foo/compile.dest/zinc
out/foo/compile.json
out/foo/compile.log
out/mill-build/...
out/mill-profile.json
out/mill-runner-state.json
out/mill-dependency-tree.json
out/mill-out-lock
out/mill-invalidation-tree.json
out/mill-chrome-profile.json
out/mill-daemon/...Task Metadata and Cached Files
Each named task (Task or Command) that is run has a representation in
the out/ directory structure. The module structure is reflected in the directories,
so that each module of your project has a uniquely associated subdirectory under the
out/ directory. For example, the foo.compile task we ran above places
its files in the out/foo/compile.* paths:
> find out/foo/compile.* -maxdepth 0
out/foo/compile.json
out/foo/compile.log
out/foo/compile.dest<task>.json
The cache-key and JSON-serialized return-value of the foo.compile task.
The return-value can also be retrieved via mill show foo.compile.
Binary blobs are typically not included in foo.json, and instead stored as separate binary files in
.dest/ which are then referenced by .json file via PathRef references.
<task>.dest/
A path for the Task to use either as a scratch space, or to place generated files that are returned
using PathRef references.
A Task should only output files within its own given foo.dest/ folder (available as Task.dest) to avoid
conflicting with another Task, but can name files within foo.dest/ arbitrarily.
<task>.log
The stdout/stderr of the Task, if any. This is also streamed to the console during
evaluation, but the terminal can get messy with many tasks running and printing logs in
parallel, so if you want the logs for a single task you can find them on disk.
<task>.super/
Holds task metadata for overridden tasks, if any. Whenever you use a super.foo() in your foo task, you
will find the metadata of the super.foo() under this directory.
The out/ folder is intentionally kept simple and user-readable.
If your build is not behaving as you would expect,
feel free to poke around the various
foo.dest/ folders to see what files are being created, or the foo.json files to see what is being returned by a
particular task.
You can also simply delete folders within out/ if you want to force portions of your project to be
rebuilt, e.g. by deleting the out/main/ or out/main/compile.* folders, but we strongly encourage you to use the clean command instead.
|
Cleaning some task state by manually deleting files under Instead, you should always give the |
Other files in the out/ directory
Apart from the build task-related files in the out folder, Mill itself places a variety
of files in the out folder under the out/mill-* prefix:
> find out/mill-* -maxdepth 0
out/mill-chrome-profile.json
out/mill-dependency-tree.json
out/mill-invalidation-tree.json
out/mill-out-lock
out/mill-profile.json
out/mill-build
out/mill-daemon
out/mill-runner-state.jsonFiles of note:
mill-profile.json
Logs the tasks run and time taken for the last Mill command you executed. This is very useful if Mill is being unexpectedly slow, and you want to find out exactly what tasks are being run. This is useful to quickly look up tasks that were run to see how long they took, whether they were cached, and if not whether their outputs changed as a result of them being run:
> cat out/mill-profile.json
[
{
"label": "mill.javalib.JvmWorkerModule/internalWorker",
"millis": ...,
"cached": true,
"valueHashChanged": false,
"dependencies": [
...
],
"inputsHash": ...
},
{
"label": "foo.compile",
"millis": ...,
"cached": false,
"valueHashChanged": false,
"dependencies": [
...
],
"inputsHash": ...,
"previousInputsHash": ...
}
]mill-chrome-profile.json
This file can be opened in any Google Chrome browser with the built-in chrome://tracing
URL to show you runtime profile of the last Mill command, so you can see what was executed
when, sequentially or in parallel, and how long it took. This is very useful for
understanding the performance of large parallel Mill builds
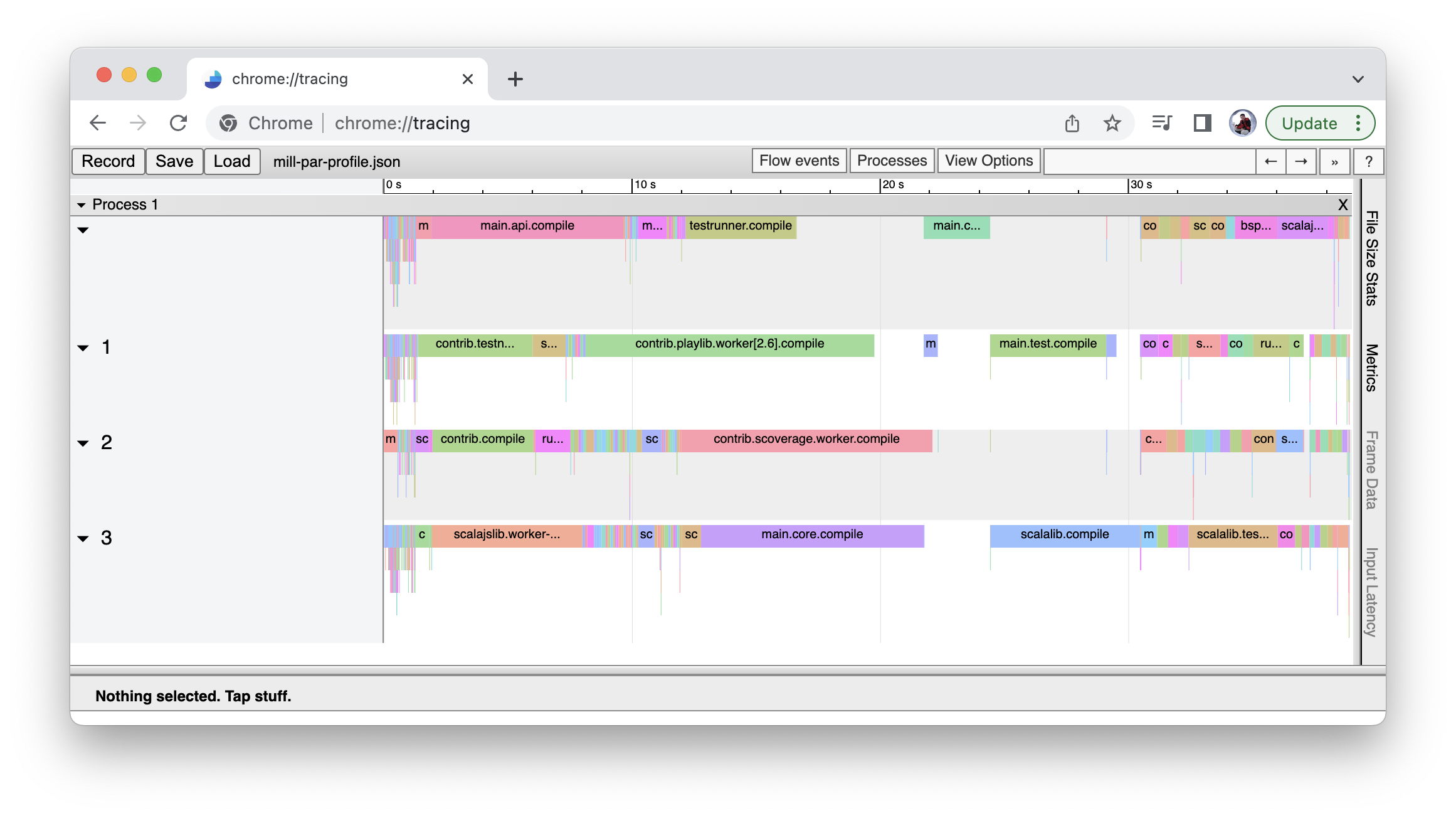
mill-chrome-profile.json complements mill-profile.json: where mill-profile.json is
most useful for point lookups of facts about the last Mill evaluation, mill-chrome-profile.json
is most useful to get a high-level overview of the runtime performance characteristics of
the tasks that were
mill-runner-state.json
Long-lived metadata about the Mill bootstrap process that persists between runs: workers, watched files, classpaths, and related data.
mill-active.json
A JSON file containing info about the active Mill process (command and process directory), used for debugging. It is present while a command is running and removed afterward.
mill-selective-execution.json
Metadata related to selective execution (input hashes and method signatures) used to decide what tasks need to run after code or input changes.
mill-dependency-tree.json
A JSON file where the root keys are the tasks directly specified by the last
./mill <selector> command, and the tree structure shows the upstream tasks and how
the root tasks depend on them. You can use this to see why a task specified by
<selector> is causing a particular upstream task to be selected.
For example, when running foo.compile above, we get a tree structure (simplified below)
that shows how foo.compile depends on foo.allSourceFiles/foo.allSources/foo.sources
(the files in the src/ folder), foo.compileClasspath/localCompileClasspath/compileResources
(i.e. the files in the compile-resources/ folder:
> cat out/mill-dependency-tree.json
{
"foo.compile": {
"foo.allSourceFiles": {
"foo.allSources": {
"foo.sources": {},
"foo.generatedSources": {}
},
"foo.wrappedSources": {}
},
"foo.compileClasspath": {
"foo.resolvedMvnDeps": {
"foo.mvnDeps": {},
...
},
...
},
...
}
}If there are multiple paths through which one task depends on another, one path is chosen arbitrarily to be shown in the spanning tree
mill-invalidation-tree.json
A JSON file where the root keys are the Mill inputs that were invalidated when the last command was run, and the tree structure shows the downstream tasks that were invalidated due to those inputs changing. This is useful to see why a task that was selected was actually run rather than being cached.
For example, above we edited the foo/src/foo/Foo.java file before running foo.compile
a second time, and thus this file shows how foo.sources invalidated foo.allSources,
foo.allSourcesFiles, and lastly foo.compile:
> cat out/mill-invalidation-tree.json
{
"foo.sources": {
"foo.allSources": {
"foo.allSourceFiles": {
"foo.compile": {},
"foo.zincIncrementalCompilation": {}
}
}
}
}Again, if there are multiple paths through which one task was invalidated by another, one path is chosen arbitrarily to be shown in the spanning tree
Code Change Invalidation
Sometimes invalidation can be caused by a code change in your build.mill/package.mill
files, rather than by a change in the project’s source files or inputs. In such cases,
mill-invalidation-tree.json will show the method-level code changes that caused the
invalidation, with def and call nodes showing how the code change propagates through
the build definition to reach the invalidated tasks.
> sed -i.bak 's/{}/{println(123)}/g' build.mill
> ./mill foo.compile # compile after changing build.mill
> cat out/mill-invalidation-tree.json
{
"def build_.package_$foo$#<init>(build_.package_)void": {
"foo.compileGeneratedSources": {
"foo.compile": {}
...In the mill-invalidation-tree.json above, we can see how the addition of the call
to scala.Predef.println caused the <init> constructor method of build_.package_.foo
to be invalidated, and ends up invalidating def build_.package_#foo() which is the method
representing the build.foo module. All tasks defined in that module (including foo.compile)
are shown as invalidated underneath.
Mill’s code-change invalidation analysis is approximate and conservative. That means that it invalidates each task when any method it calls (transitively) is changed. This may sometimes invalidate too many tasks, but it generally does not invalidate too few tasks, except in code using Java Reflection or similar techniques which the code-change analysis does not understand.
mill-console-tail
out/mill-console-tail is a rotating log file that you can tail -F to see the streaming
logs of the currently running Mill process, including the prompt that displays the currently
running tasks. This is useful if Mill is being run by some external script or workflow which
otherwise would not be streaming the status and logs to your terminal, so you can figure out
what the Mill process is doing and whether it is stuck or making progress.
mill-build/
Contains the files related ot the The Mill Meta-Build. It contains many
of thd same task-related and Mill-related files as the top-level out/ folder, but
related for compiling your build.mill rather than compiling your project’s source files.
Using another location than the out/ directory
The default location for Mill’s output directory is out/ under the project workspace.
If you’d rather use another location than out/, that lives
in a faster or a writable filesystem for example, you can change the output directory
via the MILL_OUTPUT_DIR environment variable.
package build
import mill.*
object foo extends Module {
def printDest = Task {
println(Task.dest)
}
}> MILL_OUTPUT_DIR=build-stuff/working-dir ./mill foo.printDest
...
.../build-stuff/working-dir/foo/printDest.dest