Parallelism in Mill
By default, Mill will evaluate all tasks in parallel, with the number of concurrent
tasks equal to the number of cores on your machine. You can use the
--jobs
to configure explicitly how many concurrent tasks you wish to run, or -j1 to disable
parallelism and run on a single core.
When Can Tasks Be Parallelized?
The actual amount of parallelism may depend on the structure of the build in question:
-
Tasks and modules that depend on each other have to run sequentially
-
Tasks and modules that are independent can run in parallel
In general, Mill is able to provide the most parallelism for "wide" builds with a lot of independent modules in a shallow hierarchy.
If you want to visualize the structure of your build graph, you can use
./mill visualize on the tasks you
care about. e.g. if you want to visualize the relationship between the various
.compile tasks:
$ ./mill visualize __.compile
visualize renders an SVG which lets you see how the various tasks you selected depend
(or not depend) on one another. This can be very helpful to figure out where the
bottlenecks in your build are, and from there come up with ideas of refactoring your
build to improve parallelism.
Concurrent Mill Invocations
As of Mill 1.2.0, the Mill daemon uses fine-grained per-task read/write locking rather than a
single global lock over the out/ folder. This means multiple concurrent mill commands run
against the same project (for example a command-line ./mill invocation alongside an
IDE-triggered BSP request) can run their non-conflicting tasks
in parallel, instead of one invocation having to wait for the other to finish.
Commands that mutate shared state, such as clean, init, or the various code formatters, are
marked globally exclusive: they take
the daemon-wide workspace lock so that no other invocation runs concurrently while they execute.
Running with --no-daemon instead takes a single coarse process-level lock per invocation.
Mill Chrome Profiles
Every mill run generates an output file in out/mill-chrome-profile.json that can be
loaded into the Chrome browser’s chrome://tracing page for visualization. This can make
it much easier to analyze your parallel runs to find out what’s taking the most time:
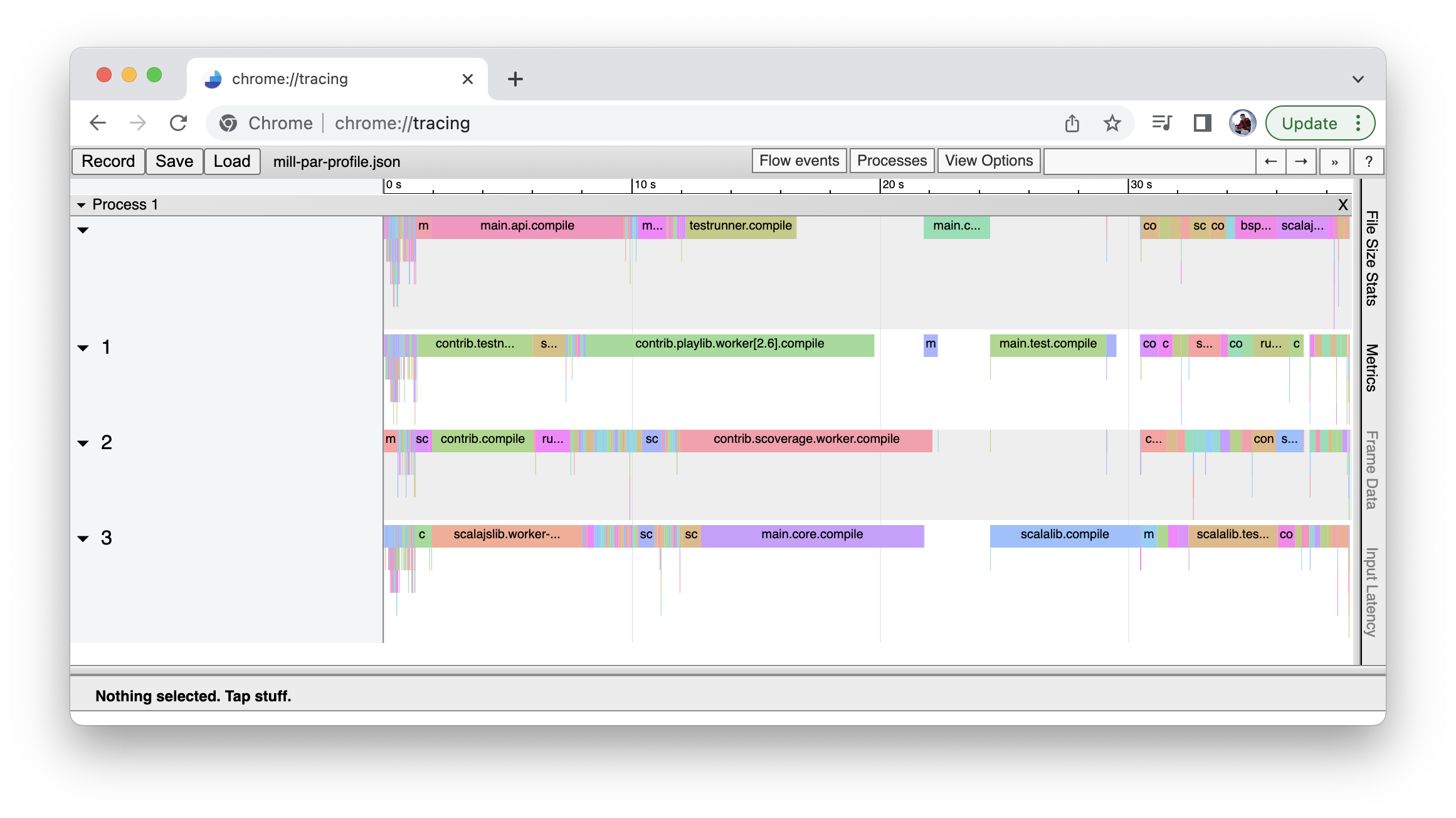
The chrome profile is great for finding bottlenecks in your parallel builds, since you
can usually see if there’s a task taking a long time before downstream tasks can begin.
These "long pole" tasks are usually good targets for optimization: e.g. a long compile
task may be improved by breaking down its module into smaller modules that can compile
independently and in parallel.
Consequences of Parallelism in Mill
Mill running tasks in parallel means that you have to take care that your code is thread safe. Your build will have multiple tasks running in parallel, and if your tasks are using shared mutable state then there is risk of race conditions and non-deterministic bugs. This is usually not a problem for most Mill code following the standard conventions, but it is worth taking note of:
-
For code written in a typical Scala style, which focuses on immutable values and pure functions, the code is typically thread safe by default. "Local" mutability e.g. within a function does not cause issues either
-
For tasks writing to the filesystem, make sure you only write to
Task.dest, which is a dedicated folder assigned to each task. This ensures that you do not have multiple tasks writing to the same files in parallel, allowing these filesystem writes to be safe and race-free even in the presence of parallelism -
For long-lived in-memory Workers, the value is initialized in a single-thread, but may be used from multiple threads concurrently. The onus is on the implementer to ensure that the worker values are safe to be used concurrently from multiple tasks: whether by wrapping mutating operations in
synchronizedblocks, using concurrent data structures likeConcurrentHashMaps, or Mill helpers like CachedFactory.
(Experimental) Forking Concurrent Futures within Tasks
Mill provides the Task.fork.async and Task.fork.await APIs for spawning async
futures within a task and aggregating their results later. This API is used by Mill
to support parallelizing test classes,
but can be used in your own tasks as well:
package build
import mill.*
def taskSpawningFutures = Task {
val f1 = Task.fork.async(dest = Task.dest / "future-1", key = "1", message = "First Future") {
logger =>
println("Running First Future inside " + os.pwd)
Thread.sleep(3000)
val res = 1
println("Finished First Future")
res
}
val f2 = Task.fork.async(dest = Task.dest / "future-2", key = "2", message = "Second Future") {
logger =>
println("Running Second Future inside " + os.pwd)
Thread.sleep(3000)
val res = 2
println("Finished Second Future")
res
}
Task.fork.await(f1) + Task.fork.await(f2)
}> ./mill show taskSpawningFutures
Running First Future inside .../out/taskSpawningFutures.dest/future-1
Running Second Future inside .../out/taskSpawningFutures.dest/future-2
Finished First Future
Finished Second Future
3Task.fork.async takes several parameters in addition to the code block to be run:
-
destis a folder for which the async future is to be run, overridingos.pwdfor the duration of the future -
keyis a short prefix prepended to log lines to let you easily identify the future’s log lines and distinguish them from logs of other futures and tasks running concurrently -
messageis a one-line description of what the future is doing -
priority: 0 means the same priority as other Mill tasks, negative values <0 mean increasingly high priority, positive values >0 mean increasingly low priority
Each block spawned by Task.fork.async is assigned a dedicated logger with its own
.log file and terminal UI integration
Futures spawned by Task.fork.async count towards Mill’s -j/--jobs concurrency limit
(which defaults to one-per-core), so you can freely use Task.fork.async without worrying
about spawning too many concurrent threads and causing CPU or memory contention. Task.fork
uses Java’s built in ForkJoinPool and ManagedBlocker infrastructure under the hood
to effectively manage the number of running threads.
While scala.concurrent and java.util.concurrent can also be used to spawn thread
pools and run async futures, Task.fork provides a way to do so that integrates with Mill’s
existing concurrency, sandboxing and logging systems. Thus you should always prefer to
run async futures on Task.fork whenever possible.